TERCERA FORMA DE NORMALIZACION
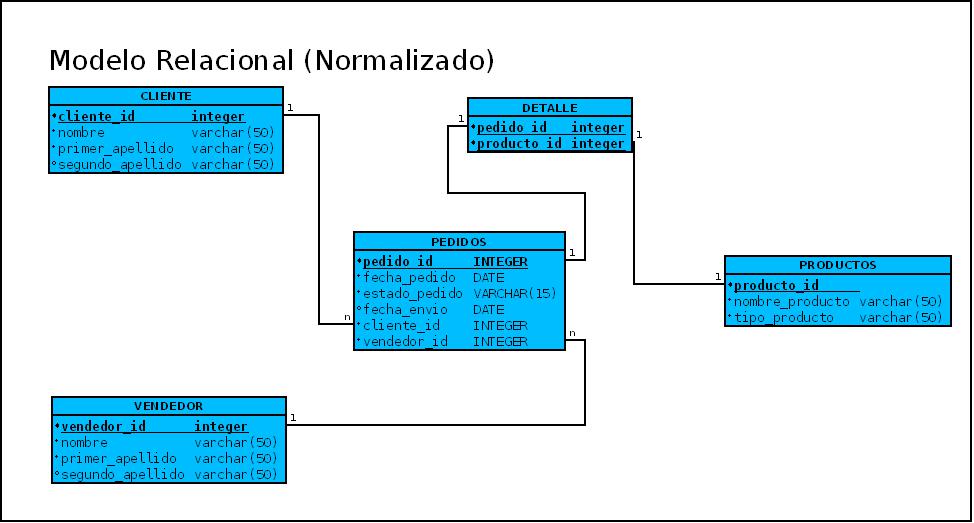
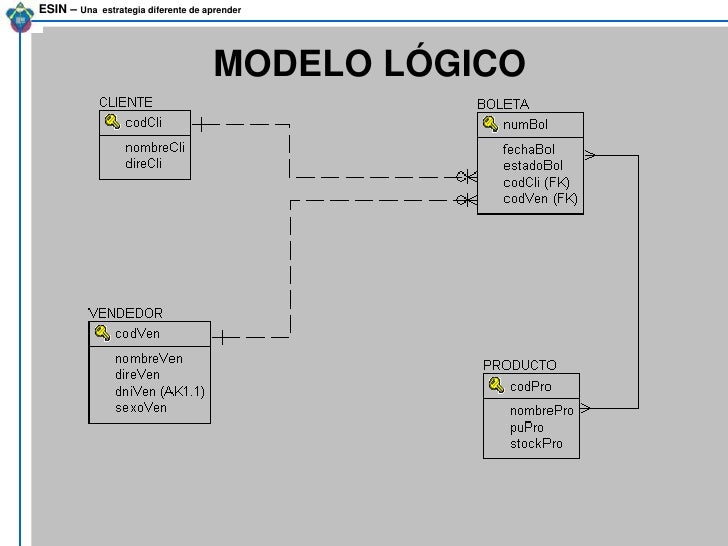
La nacionalización es el proceso mediante el cual se transforman datos complejos a un conjunto de estructuras de datos mas pequeñas, que ademas de ser mas simples y mas estables, son mas fáciles de mantener.
También se puede entender la nacionalización como una serie de reglas que sirven para ayudar a los diseñadores de bases de datos a desarrollar un esquema que minimice los problemas de lógica. cada regla esta basad en la que le antecede. La nacionalización se adopto porque el viejo estilo de poner todos lo datos en un solo lugar, como un archivo o una tabla de la base de datos, era ineficientes y conducía a errores de lógica cuando se trataban de manipular los datos.
Grado de nacionalización
existen básicamente tres niveles e nacionalización:
También se puede entender la nacionalización como una serie de reglas que sirven para ayudar a los diseñadores de bases de datos a desarrollar un esquema que minimice los problemas de lógica. cada regla esta basad en la que le antecede. La nacionalización se adopto porque el viejo estilo de poner todos lo datos en un solo lugar, como un archivo o una tabla de la base de datos, era ineficientes y conducía a errores de lógica cuando se trataban de manipular los datos.
Grado de nacionalización
existen básicamente tres niveles e nacionalización:

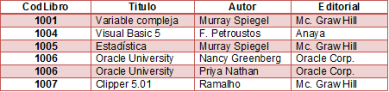
- Primera forma normal: la regla de la primera forma normal establece que las columnas repetidas deben eliminarse y colocarse en tablas separadas.
- Segunda forma normal: La regla establece que todas las dependencia parciales se deben eliminar y separar dentro de sus propias tablas. una dependencia parcial es un termino que describe a aquellos datos que no dependen de la llave primaria de la tabla para identificarlos
- Tercera forma normal: Una tabla esta normalizada en esta forma si todas las columnas que no son llave son funcional mente dependientes por completo de la llave primaria y no hay dependencias transitivas. Una dependencia transitiva es aquella en la cual existen columnas que no son llave que dependen de otras columnas que tampoco son llave
- Forma normal de boyce codd: es una forma normal utilizada en la nacionalización de bases de datos. Es una versión ligeramente mas fuerte de la 3FN. La forma normal de boyce codd requiere que no existan dependencias funcionales no triviales de los atributos que no sean un conjunto de la clave candidata.